DataBase
데이터베이스 part2 - MYSQL 완전 삭제, 데이터 모델링, 관계형 데이터 모델(릴레이션 특성, 키의 종류), MySQL 데이터 타입, SQL
jyeeee
2022. 4. 24. 15:13
MYSQL 완전 삭제
1. 윈도우키 누르고 -> 서비스 검색
2. 서비스 관련 창 -> mysql 선택 -> 서비스 중지(오른쪽버튼)
3. 윈도우키 누르고 -> 프로그램 삭제 검색
4. 프로그램 삭제 창 -> mysql 선택 -> 삭제 진행
5. C:\Program Files\MySQL 폴더 삭제
6. C:\ProgramData\MySQL 폴더 삭제 (보기-> 숨긴항목 체크)
MYSQL 다시설치
데이터 모델링
복잡한 현실 세계에 존재하는 데이터를 단순화 시켜 표현해 컴퓨터 세계의 데이터베이스로 옮기는 변환 과정

데이터 모델링의 특징
1. 추상화(Abstraction) : 현실세계를 간략하게 표현한다.
2. 단순화 ( Simple ) : 누구나 쉽게 이해할 수 있도록 표현한다.
3. 명확성(Clarity) : 명확하게 의미가 해석되어야 하고 한 가지 의미를 가져야 한다.
데이터 모델링
1. 개념적 데이터 모델 : 사람의 머리로 이해할 수 있도록 현실 세계를 개념적인 형태로 모델링하여 데이터베이스의 개념적 구조로 표현하는 도구
2. 논리적 데이터 모델 : 개념적 구조를 논리적 형태로 모델링하여 데이터베이스의 논리적 구조로 표현하는 도구

데이터 모델링(개체-관계 모델)
관계(relationship)
- 개체와 개체가 맺고 있는 의미 있는 연관성
- 개체 집합들 사이의 대응 관계, 즉 매핑(mapping)을 의미
- 예) 고객 개체와 상품 개체 간의 구매 관계
“고객은 상품을 구매한다”

데이터 모델링(관계의 유형)
관계(relationship)
- 일대일 (1:1) 관계
- 일대다 (1:N) 관계
- 다대다 (N:M) 관계




관계형 데이터 모델 – 데이터 베이스의 구성
1. 데이터베이스 스키마(database schema)
- 데이터베이스의 전체구조
- 데이터베이스를 구성하는 릴레이션 스키마의 모음
2. 데이터베이스 인스턴스(database instance)
- 데이터베이스를 구성하는 릴레이션 인스턴스의 모음

관계형 데이터 모델 – 릴레이션의 특성
1. 튜플의 유일성
- > 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다.
즉 식별자(key)가 없는 테이블은 존재할 수 없다.
2. 튜플의 무순서 : 하나의 릴레이션에서 튜플 사이의 순서는 무의미하다.
3. 속성의 무순서 : 하나의 릴레이션에서 속성 사이의 순서는 무의미하다.
4. 속성의 원자성
-> 모든 속성은 반드시 원자 값(=더이상 분리될 수 없는 값)을 가져야 합니다.
널(Null)값도 원자 값으로 간주합니다.
관계형 데이터 모델 – 키, 키의 특성
키 : 릴레이션에서 튜플들을 유일하게 구별하는 속성 또는 속성들의 집합
1. 유일성(uniqueness)
- 하나의 키 값으로 하나의 튜플만을 유일하게 식별
- 한 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 함
2. 최소성(minimality)
- 꼭 필요한 최소한의 속성들로만 키를 구성
→ 한 릴레이션에 기본키를 하나만 설정했을 경우 최소성을 만족
관계형 데이터 모델 – 키의 종류

테이블에는 하나의 기본키만 잡아주는 것이 좋다. 복합키가 있을 경우, 문제가 생길 가능성이 크다.
1. 기본키(primary key)
- 후보키 중에서 기본적으로 사용하기 위해 선택한 키
예) 고객 릴레이션의 기본키: 고객아이디
2. 후보키(candidate key)
- 유일성과 최소성을 만족하는 속성 또는 속성들의 집합
예) 고객 릴레이션의 후보키: 고객아이디, (고객이름, 주소) 등
3. 대체키(alternate key)
- 기본키로 선택되지 못한 후보키
예) 고객 릴레이션의 대체키: (고객이름, 주소)
4. 슈퍼키(super key)
- 유일성을 만족하는 속성 또는 속성들의 집합
예) 고객 릴레이션의 슈퍼키: 고객아이디, (고객아이디, 고객이름), (고객이름, 주소) 등

5. 외래키(foreign key)
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
- 릴레이션들 간의 관계를 표현
. 참조하는 릴레이션: 외래키를 가진 릴레이션
. 참조되는 릴레이션: 외래키가 참조하는 기본키를 가진 릴레이션
- 일반적인 속성은 외래키로 참조하려면, 기본키로 잡아줘야 한다.
관계형 데이터 모델 – 제약조건

무결성 제약조건(integrity constraint)
- 데이터의 무결성을 보장하고 일관된 상태로 유지하기 위한 규칙
- 무결성 : 데이터를 결함이 없는 상태
즉, 정확하고 유효하게 유지하는 것
1. 도메인 무결성 제약조건(Domain constraint)
- 특정 속성의 값이 그 속성이 정의된 도메인에 속한 값이어야 한다는 규칙
- null 값은 허용됨 ( not null이 아닌 경우)

2. 개체 무결성 제약조건(entity integrity constraint)
- 기본키를 구성하는 모든 속성은 널 값을 가질 수 없는 규칙

3. 참조 무결성 제약조건(referential integrity constraint)
- 외래키는 참조할 수 없는 값을 가질 수 없는 규칙
- but, 외래키의 속성이 널 값을 가진다고 해서 참조 무결성을 위반한 것은 아니다.
- RESTRICTED : 레코드를 변경 또는 삭제하고자 할 때 해당 레코드를 참조하고 있는 개체가 있다면, 변경 또는 삭제 연산을 취소
- CASECADE : 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체도 변경 또는 삭제
- SETNULL - 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하고 있는 개체의 값을 NULL로 설정









-- 문자와 문자를 더함 (정수로 변환되서 연산됨)
SELECT '100' + '200’ ;
-- 문자와 문자를 연결 (문자로 처리)
SELECT CONCAT('100', '200’);
-- 정수와 문자를 연결 (정수가 문자로 변환되서 처리)
SELECT CONCAT(100, '200’);
-- 정수인 2로 변환되어서 비교
SELECT 1 > '2mega’;
-- 정수인 2로 변환되어서 비교
SELECT 3 > '2MEGA’;
-- 문자는 0으로 변환됨
SELECT 0 = 'mega2';
Test
- 테스트하고 싶을 땐, select 키워드를 포함하여 실행해 볼 것.
- 함수는 외우는 것이 아니라, 찾아보면 된다. 구문을 알자
1. LIMIT : 테이블 데이터 출력 갯수 제한
- 인자를 1개만 쓸 경우 : 행
- 인자를 2개 쓸 경우 : 인덱스번호, 갯수(인덱스 번호부터 몇개를 출력할 것인지)
SELECT
u.u_id
,u.u_pw
,u.u_name
,u.u_birth
FROM
tb_user AS u
ORDER BY u.u_id DESC
LIMIT 5;
/* limit 출력갯수 제한 키워드 */
SELECT
u.u_id
,u.u_pw
,u.u_name
,u.u_birth
FROM
tb_user AS u
ORDER BY u.u_id DESC
LIMIT 10, 10;
2. DISTINCT : 중복 데이터 하나만 조회
/* DISTINCT 중복제거 키워드 */
SELECT
DISTINCT u.u_add
FROM
tb_user AS u;
3. GROUP BY : 데이터 그룹출력
COUNT : 하나의 필드를 기준으로 갯수나 통계
/* GROUP BY 키워드 */
SELECT
u_add AS '주소'
,COUNT(u_id) AS '고객분포수'
FROM
tb_user
GROUP BY u_add;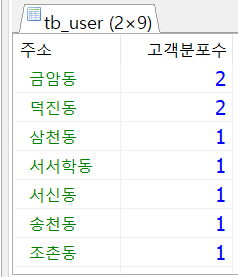
4. 데이터 타입
① 날짜 데이터
- DATE : 'YYYY-MM-DD'
- TIME : 'HH:MM:SS'
- DATETIME : 'YYYY-MM-DD HH:MM:SS'
- TIMESTAMP : 'YYYY-MM-DD HH:MM:SS'
Time_zone 시스템 변수와 관련 있으며 UTC 변환 저장
- YEAR : 'YYYY'
② 집계 함수
- COUNT (DISTINCT) : 행의 개수를 센다.(중복은 1개만 인정)
- COUNT(*) : 행의 레코드 갯수(null포함)
- COUNT(1) : 행의 레코드 갯수(null포함)
- COUNT(컬럼) : null값을 제외한 행의 레코드 갯수
③ My SQL 내장함수
- CAST : 데이터 형식 변환 함수
SELECT CAST('2022-10-19 12:35:29.123' AS DATE) AS 'DATE' ;
- CONCAT : 문자열 연결함수
SELECT
CONCAT(m.m_id, ' : ', m.m_name) AS '아이디:이름'
FROM
tb_member m;
- 제어 흐름 함수(IF, IFNULL, NULLIF, CASE WHEN)
④ 문자열 함수 (TRIM, REPLACE, CONCAT 3가지 함수만 주로 사용,SUBSTRING, SUBSTRING_INDEX )
- TRIM : 앞뒤 공백 제거
- REPLACE : 문자 사이사이 공백은 REPLACE를 쓰는 게 좋다.

- SUBSTRING

- SUBSTRING_INDEX
